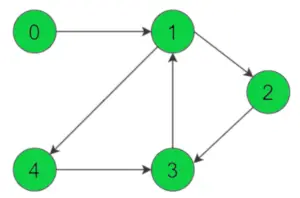
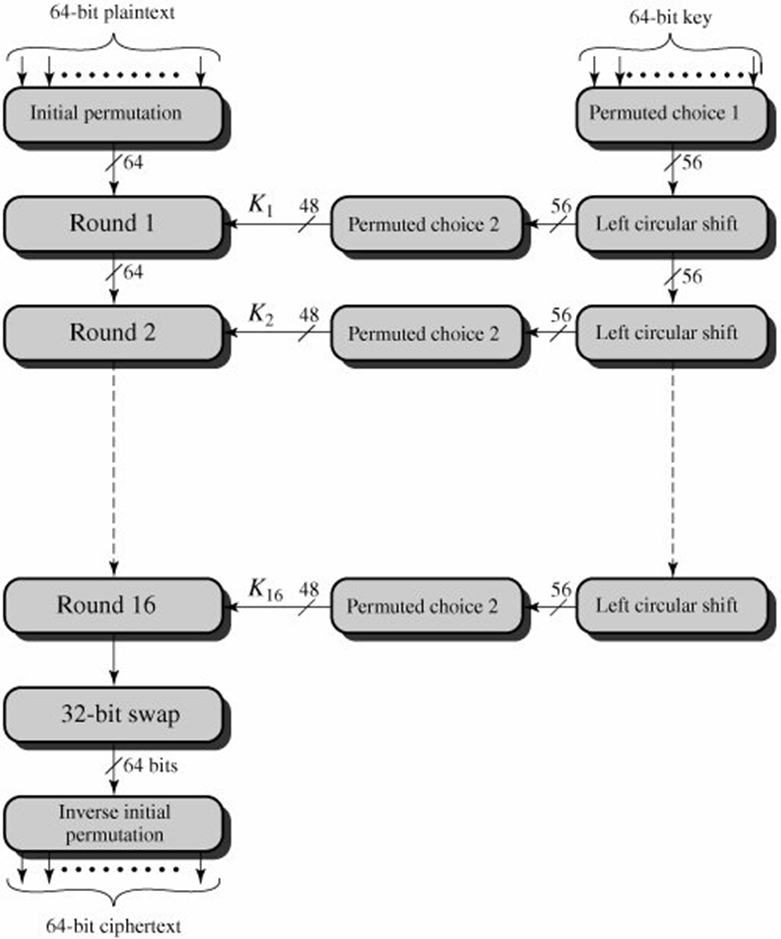
Data Encryption Standard is a symmetric-key algorithm for the encrypting the data. It comes under block cipher algorithm which follows Feistel structure. Here is the block diagram of Data Encryption Standard.
![DES Algorithm Block Diagram]()
Fig1: DES Algorithm Block Diagram [Image Source: Cryptography and Network Security Principles and Practices 4th Ed by William Stallings]
Explanation for above diagram: Each character of plain text converted into binary format. Every time we take 64 bits from that and give as input to DES algorithm, then it processed through 16 rounds and then converted to cipher text.
Initial Permutation: 64 bit plain text goes under initial permutation and then given to round 1. Since initial permutation step receiving 64 bits, it contains an 1×64 matrix which contains numbers from 1 to 64 but in shuffled order. After that, we arrange our original 64 bit text in the order mentioned in that matrix. [You can see the matrix in below code]
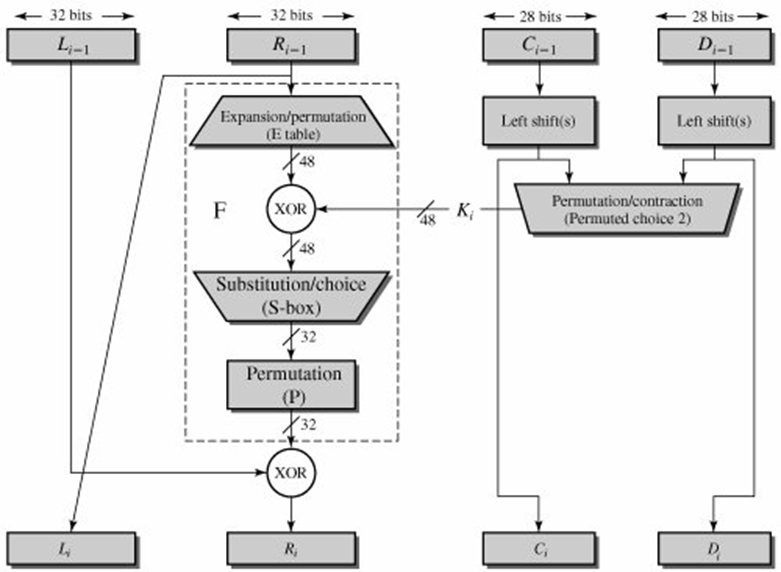
After initial permutation, 64 bit text passed through 16 rounds. In each round it processed with 48 bit key. That means we need total 16 sub keys, one for each round. See below diagram, it will show what happening in each round of algorithm.
![Single Round of DES Algorithm]()
Fig2: Single Round of DES Algorithm. [Image Source: Cryptography and Network Security Principles and Practices 4th Ed by William Stallings]
Round i: In each round 64bit text divided into two 32bit parts. Left and Right. You can see in diagram Li-1 and Ri-1. As algorithm says, Right 32bits goes under Expansion Permutation.
Expansion Permutation: Right side 32bit part of text given to expansion permutation. It will produce a 48bit text as output. i.e. 16bits added in this step. Some bits below 32 are repeated and arranged in an 1×48 matrix form. We rearrange 32bit text by following the order of that matrix. [See the matrix in below code]
After expansion permutation we have to XOR the output 48bit with a 48bit sub key. Let see how that 48bit sub key generating from 64bit original key.
Permutated Choice 1: Initially we take a 64 bit key and then apply to permutated choice 1. It contains a 1×56 matrix but with shuffled 1 to 64 numbers except multiples of number 8. i.e. 8, 16, 24, 32, 40, 48, 56, 64 will be discarded. Remaining 64-8 = 56 number will be there in 1×56 matrix. We rearrange key in matrix specified order. [You can see the matrix in below code]
Left Circular Shift: 56bit key from permutated choice 1 given to left circular shift operation. Here that 56bit key divided into two equal halves of each 28bit. These 28bits shifted depends upon the round number. We already have the data that in each round how many bits circularly we have to shift. You can see this data in shifts array in code.
Permutated Choice 2: Result of Left circular shift 56bit key given to permutated choice 2. This step will produce 48bit sub key. For this it has an 1×48 matrix, in which out of 56, some random 8 bits will be discarded. And remaining 48 will be there. According to this bit positions we have to rearrange the key. You can see this matrix in below code.
Now output of permutated choice 2 will be Xor with output of expansion permutation, which results a 48bit one. This 48bit again reduced to 32bit using Substitution boxes [called S box].
Substitution boxes [S box]: In DES algorithm we have 8 S boxes. Input for S box is 48bit. And output from S box is 32 bit. The input 48 bit will be divided equally to 8 s boxes from s1, s2, … s8. So each s box will get 48/8= 6 bits as input. This Each S box reduce 6 bits to 4 bits. i.e input for each S box is 6 bits and output is 4 bits. Finally, 8*4 = 32 bit. Which is final output of S box operation.
Let see how 6bits converted to 4 bits from S box. S box is an 4×16 matrix containing numbers in range 0 to 15. Take example, assume input 6 bits for S box are 011011. In this first and last bit together represents row number. Since maximum number with two bits is 3, S box also contains 0 to 3 rows total of 4. And middle 4 numbers together represent column number. Since maximum number with 4 bits is 15, S box also contains columns 0 to 15 total of 16. So here first and last bit = 01 i.e. row number 1 and middle 4 bits 1101= 13 i.e. column number 13. So for this input the number positioned at row 1 and column 13 will be picked. As mentioned earlier S box only contains number in range 0 to 15. All can be represented in 4 bits. So picked number 4 bits are output for the S box. See the code for all S boxes.
Permutation: After getting output from all S boxes, we are applying again permutation. Here also a matrix with different arrangements will be there, we have to arrange according to that.
Final XOR: After this permutation, take the left half which initially divided 64bit text to two halves. Do XOR with this permutation output to left 32bit part. This result is new Right part. And Right 32bit part which passed through all permutation will be come as new Left Part. These 2 parts will be the inputs for the second round. Same as keys also, the parts before left shift are next round input keys.
All this explanation for a single round for a 62bit plain text. Like this, it passes through total 16 rounds.
32 bit swap: After completion of 16 rounds, final 64 bits divided into two 32 bit parts and they swap each other.
Inverse Initial Permutation: Here also a matrix will be there, in which bits are just shuffled. No adding or subtracting bits. See the code for this matrix.
Program for DES Algorithm in C
#include <stdio.h>
int Original_key [64] = { // you can change key if required
0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0,
0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1,
1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0,
1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1
};
int Permutated_Choice1[56] = {
57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27,
19, 11, 3, 60, 52, 44, 36,
63, 55, 47, 39, 31, 23, 15,
7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29,
21, 13, 5, 28, 20, 12, 4
};
int Permutated_Choice2[48] = {
14, 17, 11, 24, 1, 5,
3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8,
16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55,
30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53,
46, 42, 50, 36, 29, 32
};
int Iintial_Permutation [64] = {
58, 50, 42, 34, 26, 18, 10, 2,
60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6,
64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9, 1,
59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5,
63, 55, 47, 39, 31, 23, 15, 7
};
int Final_Permutation[] =
{
40, 8, 48, 16, 56, 24, 64, 32,
39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30,
37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28,
35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26,
33, 1, 41, 9, 49, 17, 57, 25
};
int P[] =
{
16, 7, 20, 21,
29, 12, 28, 17,
1, 15, 23, 26,
5, 18, 31, 10,
2, 8, 24, 14,
32, 27, 3, 9,
19, 13, 30, 6,
22, 11, 4, 25
};
int E[] =
{
32, 1, 2, 3, 4, 5,
4, 5, 6, 7, 8, 9,
8, 9, 10, 11, 12, 13,
12, 13, 14, 15, 16, 17,
16, 17, 18, 19, 20, 21,
20, 21, 22, 23, 24, 25,
24, 25, 26, 27, 28, 29,
28, 29, 30, 31, 32, 1
};
int S1[4][16] =
{
14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7,
0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8,
4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0,
15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13
};
int S2[4][16] =
{
15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10,
3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5,
0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15,
13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9
};
int S3[4][16] =
{
10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8,
13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1,
13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7,
1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12
};
int S4[4][16] =
{
7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15,
13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9,
10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4,
3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14
};
int S5[4][16] =
{
2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9,
14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6,
4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14,
11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3
};
int S6[4][16] =
{
12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11,
10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8,
9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6,
4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13
};
int S7[4][16]=
{
4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1,
13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6,
1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2,
6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12
};
int S8[4][16]=
{
13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7,
1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2,
7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8,
2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11
};
int shifts_for_each_round[16] = { 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1 };
int _56bit_key[56];
int _48bit_key[17][48];
int text_to_bits[99999], bits_size=0;
int Left32[17][32], Right32[17][32];
int EXPtext[48];
int XORtext[48];
int X[8][6];
int X2[32];
int R[32];
int chiper_text[64];
int encrypted_text[64];
int XOR(int a, int b) {
return (a ^ b);
}
void Dec_to_Binary(int n)
{
int binaryNum[1000];
int i = 0;
while (n > 0) {
binaryNum[i] = n % 2;
n = n / 2;
i++;
}
for (int j = i - 1; j >= 0; j--) {
text_to_bits[bits_size++] = binaryNum[j];
}
}
int F1(int i)
{
int r, c, b[6];
for (int j = 0; j < 6; j++)
b[j] = X[i][j];
r = b[0] * 2 + b[5];
c = 8 * b[1] + 4 * b[2] + 2 * b[3] + b[4];
if (i == 0)
return S1[r][c];
else if (i == 1)
return S2[r][c];
else if (i == 2)
return S3[r][c];
else if (i == 3)
return S4[r][c];
else if (i == 4)
return S5[r][c];
else if (i == 5)
return S6[r][c];
else if (i == 6)
return S7[r][c];
else if (i == 7)
return S8[r][c];
}
int PBox(int pos, int bit)
{
int i;
for (i = 0; i < 32; i++)
if (P[i] == pos + 1)
break;
R[i] = bit;
}
int ToBits(int value)
{
int k, j, m;
static int i;
if (i % 32 == 0)
i = 0;
for (j = 3; j >= 0; j--)
{
m = 1 << j;
k = value & m;
if (k == 0)
X2[3 - j + i] = '0' - 48;
else
X2[3 - j + i] = '1' - 48;
}
i = i + 4;
}
int SBox(int XORtext[])
{
int k = 0;
for (int i = 0; i < 8; i++)
for (int j = 0; j < 6; j++)
X[i][j] = XORtext[k++];
int value;
for (int i = 0; i < 8; i++)
{
value = F1(i);
ToBits(value);
}
}
void expansion_function(int pos, int bit)
{
for (int i = 0; i < 48; i++)
if (E[i] == pos + 1)
EXPtext[i] = bit;
}
void cipher(int Round, int mode)
{
for (int i = 0; i < 32; i++)
expansion_function(i, Right32[Round - 1][i]);
for (int i = 0; i < 48; i++)
{
if (mode == 0)
XORtext[i] = XOR(EXPtext[i], _48bit_key[Round][i]);
else
XORtext[i] = XOR(EXPtext[i], _48bit_key[17 - Round][i]);
}
SBox(XORtext);
for (int i = 0; i < 32; i++)
PBox(i, X2[i]);
for (int i = 0; i < 32; i++)
Right32[Round][i] = XOR(Left32[Round - 1][i], R[i]);
}
void finalPermutation(int pos, int bit)
{
int i;
for (i = 0; i < 64; i++)
if (Final_Permutation[i] == pos + 1)
break;
encrypted_text[i] = bit;
}
void Encrypt_each_64_bit (int plain_bits [])
{
int IP_result [64] , index=0;
for (int i = 0; i < 64; i++) {
IP_result [i] = plain_bits[ Iintial_Permutation[i] ];
}
for (int i = 0; i < 32; i++)
Left32[0][i] = IP_result[i];
for (int i = 32; i < 64; i++)
Right32[0][i - 32] = IP_result[i];
for (int k = 1; k < 17; k++)
{ // processing through all 16 rounds
cipher(k, 0);
for (int i = 0; i < 32; i++)
Left32[k][i] = Right32[k - 1][i]; // right part comes as it is to next round left part
}
for (int i = 0; i < 64; i++)
{ // 32bit swap as well as Final Inverse Permutation
if (i < 32)
chiper_text[i] = Right32[16][i];
else
chiper_text[i] = Left32[16][i - 32];
finalPermutation(i, chiper_text[i]);
}
for (int i = 0; i < 64; i++)
printf("%d", encrypted_text[i]);
}
void convert_Text_to_bits(char *plain_text){
for(int i=0;plain_text[i];i++){
int asci = plain_text[i];
Dec_to_Binary(asci);
}
}
void key56to48(int round, int pos, int bit)
{
int i;
for (i = 0; i < 56; i++)
if (Permutated_Choice2[i] == pos + 1)
break;
_48bit_key[round][i] = bit;
}
int key64to56(int pos, int bit)
{
int i;
for (i = 0; i < 56; i++)
if (Permutated_Choice1[i] == pos + 1)
break;
_56bit_key[i] = bit;
}
void key64to48(int key[])
{
int k, backup[17][2];
int CD[17][56];
int C[17][28], D[17][28];
for (int i = 0; i < 64; i++)
key64to56(i, key[i]);
for (int i = 0; i < 56; i++)
if (i < 28)
C[0][i] = _56bit_key[i];
else
D[0][i - 28] = _56bit_key[i];
for (int x = 1; x < 17; x++)
{
int shift = shifts_for_each_round[x - 1];
for (int i = 0; i < shift; i++)
backup[x - 1][i] = C[x - 1][i];
for (int i = 0; i < (28 - shift); i++)
C[x][i] = C[x - 1][i + shift];
k = 0;
for (int i = 28 - shift; i < 28; i++)
C[x][i] = backup[x - 1][k++];
for (int i = 0; i < shift; i++)
backup[x - 1][i] = D[x - 1][i];
for (int i = 0; i < (28 - shift); i++)
D[x][i] = D[x - 1][i + shift];
k = 0;
for (int i = 28 - shift; i < 28; i++)
D[x][i] = backup[x - 1][k++];
}
for (int j = 0; j < 17; j++)
{
for (int i = 0; i < 28; i++)
CD[j][i] = C[j][i];
for (int i = 28; i < 56; i++)
CD[j][i] = D[j][i - 28];
}
for (int j = 1; j < 17; j++)
for (int i = 0; i < 56; i++)
key56to48(j, i, CD[j][i]);
}
int main(){
char plain_text[] = "tomarrow we wiil be declaring war";
convert_Text_to_bits(plain_text);
key64to48(Original_key); // it creates all keys for all rounds
int _64bit_sets = bits_size/64;
printf("Decrypted output is\n");
for(int i=0;i<= _64bit_sets ;i++) {
Encrypt_each_64_bit (text_to_bits + 64*i);
}
return 0;
}Output
Decrypted output is
0000111001101001001100011010111010010110111010111111111000010111001011111011111101010011011101011011000000111011100100000010110101000101011000011001000000101000001010011110101001011000111010011001110010110011011110110001101110000000001000001001000110111010
The post Data Encryption Standard (DES) Algorithm appeared first on The Crazy Programmer.















 is not polynomial, this is an extended version.
is not polynomial, this is an extended version.